Background
In a simple and perfect world, the development of a project would proceed linearly, as shown in figure 1.
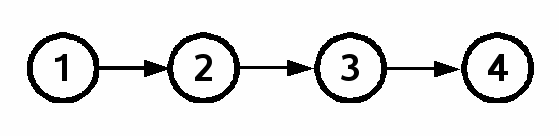 Figure 1 |
Each circle represents a check-in. For the sake of clarity, the check-ins are given small consecutive numbers. In a real system, of course, the check-in numbers would be 40-character SHA1 hashes since it is not possible to allocate collision-free sequential numbers in a distributed system. But as sequential numbers are easier to read, we will substitute them for the 40-character SHA1 hashes in this document.
The arrows in figure 1 show the evolution of a project. The initial check-in is 1. Check-in 2 is derived from 1. In other words, check-in 2 was created by making edits to check-in 1 and then committing those edits. We say that 2 is a child of 1 and that 1 is a parent of 2. Check-in 3 is derived from check-in 2, making 3 a child of 2. We say that 3 is a descendant of both 1 and 2 and that 1 and 2 are both ancestors of 3.
DAGs
The graph of check-ins is a directed acyclic graph commonly shortened to DAG. Check-in 1 is the root of the DAG since it has no ancestors. Check-in 4 is a leaf of the DAG since it has no descendants. (We will give a more precise definition later of "leaf.")
Alas, reality often interferes with the simple linear development of a project. Suppose two programmers make independent modifications to check-in 2. After both changes are committed, the check-in graph looks like figure 2:
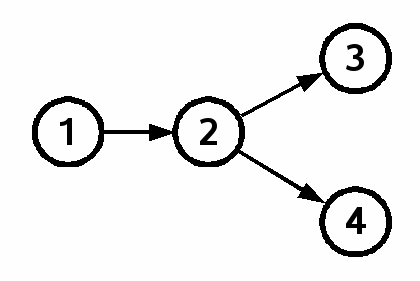 Figure 2 |
The graph in figure 2 has two leaves: check-ins 3 and 4. Check-in 2 has two children, check-ins 3 and 4. We call this state a fork.
Fossil tries to prevent forks. Suppose two programmers named Alice and Bob are each editing check-in 2 separately. Alice finishes her edits first and commits her changes, resulting in check-in 3. Later, when Bob attempts to commit his changes, fossil verifies that check-in 2 is still a leaf. Fossil sees that check-in 3 has occurred and aborts Bob's commit attempt with a message "would fork." This allows Bob to do a "fossil update" which pulls in Alice's changes, merging them into his own changes. After merging, Bob commits check-in 4 as a child of check-in 3. The result is a linear graph as shown in figure 1. This is how CVS works. This is also how fossil works in "autosync" mode.
But perhaps Bob is off-network when he does his commit, so he has no way of knowing that Alice has already committed her changes. Or, it could be that Bob has turned off "autosync" mode in Fossil. Or, maybe Bob just doesn't want to merge in Alice's changes before he has saved his own, so he forces the commit to occur using the "--force" option to the fossil commit command. For any of these reasons, two commits against check-in 2 have occurred and now the DAG has two leaves.
So which version of the project is the "latest" in the sense of having the most features and the most bug fixes? When there is more than one leaf in the graph, you don't really know. So we like to have graphs with a single leaf.
To resolve this situation, Alice can use the fossil merge command to merge in Bob's changes in her local copy of check-in 3. Then she can commit the results as check-in 5. This results in a DAG as shown in figure 3.
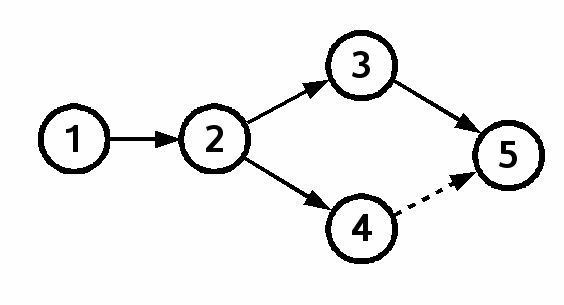 Figure 3 |
Check-in 5 is a child of check-in 3 because it was created by editing check-in 3. But check-in 5 also inherits the changes from check-in 4 by virtue of the merge. So we say that check-in 5 is a merge child of check-in 4 and that it is a direct child of check-in 3. The graph is now back to a single leaf (check-in 5).
We have already seen that if fossil is in autosync mode then Bob would have been warned about the potential fork the first time he tried to commit check-in 4. If Bob had updated his local check-out to merge in Alice's check-in 3 changes, then committed, then the fork would have never occurred. The resulting graph would have been linear, as shown in figure 1. Really the graph of figure 1 is a subset of figure 3. Hold your hand over the check-in 4 circle of figure 3 and then figure 3 looks exactly like figure 1 (except that the leaf has a different check-in number, but that is just a notational difference - the two check-ins have exactly the same content). In other words, figure 3 is really a superset of figure 1. The check-in 4 of figure 3 captures additional state which is omitted from figure 1. Check-in 4 of figure 3 holds a copy of Bob's local checkout before he merged in Alice's changes. That snapshot of Bob's changes, which is independent of Alice's changes, is omitted from figure 1. Some people say that the approach taken in figure 3 is better because it preserves this extra intermediate state. Others say that the approach taken in figure 1 is better because it is much easier to visualize a linear line of development and because the merging happens automatically instead of as a separate manual step. We will not take sides in that debate. We will simply point out that fossil enables you to do it either way.
Forking Versus Branching
Having more than one leaf in the check-in DAG is called a "fork." This is usually undesirable and either avoided entirely, as in figure 1, or else quickly resolved as shown in figure 3. But sometimes, one does want to have multiple leaves. For example, a project might have one leaf that is the latest version of the project under development and another leaf that is the latest version that has been tested. When multiple leaves are desirable, we call this branching instead of forking. Figure 4 shows an example of a project where there are two branches, one for development work and another for testing.
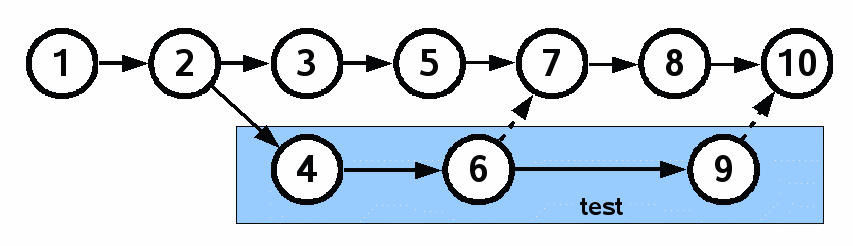 Figure 4 |
The hypothetical scenario of figure 4 is this: The project starts and progresses to a point where (at check-in 2) it is ready to enter testing for its first release. In a real project, of course, there might be hundreds or thousands of check-ins before a project reaches this point, but for simplicity of presentation we will say that the project is ready after check-in 2. The project then splits into two branches that are used by separate teams. The testing team, using the blue branch, finds and fixes a few bugs. This is shown by check-ins 6 and 9. Meanwhile the development team, working on the top uncolored branch, is busy adding features for the second release. Of course, the development team would like to take advantage of the bug fixes implemented by the testing team. So periodically, the changes in the test branch are merged into the dev branch. This is shown by the dashed merge arrows between check-ins 6 and 7 and between check-ins 9 and 10.
In both figures 2 and 4, check-in 2 has two children. In figure 2, we call this a "fork." In diagram 4, we call it a "branch." What is the difference? As far as the internal fossil data structures are concerned, there is no difference. The distinction is in the intent. In figure 2, the fact that check-in 2 has multiple children is an accident that stems from concurrent development. In figure 4, giving check-in 2 multiple children is a deliberate act. So, to a good approximation, we define forking to be by accident and branching to be by intent. Apart from that, they are the same.
Tags And Properties
Tags and properties are used in fossil to help express the intent, and thus to distinguish between forks and branches. Figure 5 shows the same scenario as figure 4 but with tags and properties added:
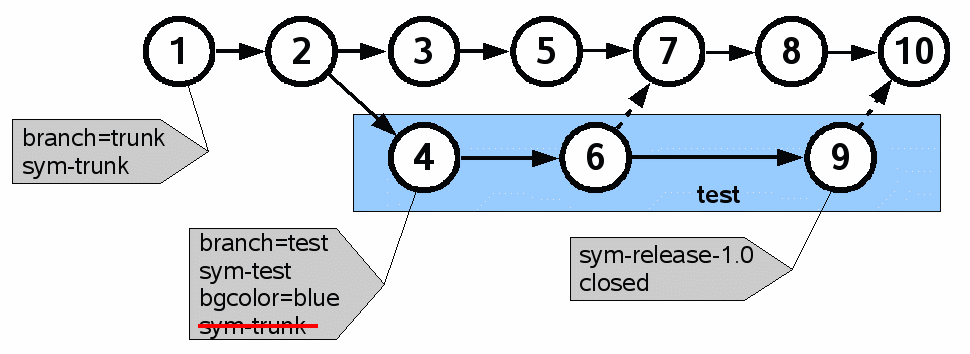 Figure 5 |
A tag is a name that is attached to a check-in. A property is a name/value pair. Internally, fossil implements tags as properties with a NULL value. So, tags and properties really are much the same thing, and henceforth we will use the word "tag" to mean either a tag or a property.
A tag can be a one-time tag, a propagating tag or a cancellation tag. A one-time tag only applies to the check-in to which it is attached. A propagating tag applies to the check-in to which it is attached and also to all direct descendants of that check-in. A direct descendant is a descendant through direct children. Tags propagation does not cross merges. Tag propagation also stops as soon as it encounters another check-in with the same tag. A cancellation tag is attached to a single check-in in order to either override a one-time tag that was previously placed on that same check-in, or to block tag propagation from an ancestor.
Every repository is created with a single empty check-in that has two propagating tags. In figure 5, that initial empty check-in is check-in 1. The branch tag tells (by its value) what branch the check-in is a member of. The default branch is called "trunk." All tags that begin with "sym-" are symbolic name tags. When a symbolic name tag is attached to a check-in, that allows you to refer to that check-in by its symbolic name rather than by its 40-character SHA1 hash name. When a symbolic name tag propagates (as does the sym-trunk tag) then referring to that name is the same as referring to the most recent check-in with that name. Thus the two tags on check-in 1 cause all descendants to be in the "trunk" branch and to have the symbolic name "trunk."
Check-in 4 has a branch tag which changes the name of the branch to "test." The branch tag on check-in 4 propagates to check-ins 6 and 9. But because tag propagation does not follow merge links, the branch=test tag does not propagate to check-ins 7, 8, or 10. Note also that the branch tag on check-in 4 blocks the propagation of branch=trunk so that it cannot reach check-ins 6 or 9. This causes check-ins 4, 6, and 9 to be in the "test" branch and all others to be in the "trunk" branch.
Check-in 4 also has a sym-test tag, which gives the symbolic name "test" to check-ins 4, 6, and 9. Because tags do not propagate across merges, check-ins 7, 8, and 10 do not inherit the sym-test tag and are hence not known by the name "test." To prevent the sym-trunk tag from propagating from check-in 1 into check-ins 4, 6, and 9, there is a cancellation tag for sym-trunk on check-in 4. The net effect is that check-ins on the trunk go by the symbolic name of "trunk" and check-ins on the test branch go by the symbolic name "test."
The bgcolor=blue tag on check-in 4 causes the background color of timelines to be blue for check-in 4 and its direct descendants.
Figure 5 also shows two one-time tags on check-in 9. (The diagram does not make a graphical distinction between one-time and propagating tags.) The sym-release-1.0 tag means that check-in 9 can be referred to using the more meaningful name "release-1.0." The closed tag means that check-in 9 is a "closed leaf." A closed leaf is a leaf that should never have direct children.
Review Of Terminology
- Branch
A branch is a set of check-ins with the same value for their "branch" property.
- Leaf
A leaf is a check-in with no children in the same branch.
- Closed Leaf
A closed leaf is any leaf with the closed tag. These leaves are intended to never be extended with descendants and hence are omitted from lists of leaves in the command-line and web interface.
- Open Leaf
A open leaf is a leaf that is not closed.
- Fork
A fork is when a check-in has two or more direct (non-merge) children in the same branch.
- Branch Point
A branch point occurs when a check-in has two or more direct (non-merge) children in different branches. A branch point is similar to a fork, except that the children are in different branches.
Check-in 4 of figure 3 is not a leaf because it has a child (check-in 5) in the same branch. Check-in 9 of figure 5 also has a child (check-in 10) but that child is in a different branch, so check-in 9 is a leaf. Because of the closed tag on check-in 9, it is a closed leaf.
Check-in 2 of figure 3 is considered a "fork" because it has two children in the same branch. Check-in 2 of figure 5 also has two children, but each child is in a different branch, hence in figure 5, check-in 2 is considered a "branch point."
Differences With Other DVCSes
Fossil keeps all check-ins on a single DAG. Branches are identified with tags. This means that check-ins can be freely moved between branches simply by altering their tags.
Most other DVCSes maintain a separate DAG for each branch.